
Получение морфируемой 3D-модели лица на основе фотографии в произвольном ракурсе
Привет, Хабр! Представляю вашему вниманию перевод статьи «
Learning 3D Face Morphable Model Out of 2D Images».
Трёхмерная морфируемая модель лица (3D Morphable Model, далее 3DMM) — это статистическая модель структуры и текстуры лица, которая используются компьютерном зрении, компьютерной графике, при анализе человеческого поведения и в пластической хирургии.
Неповторимость каждой черты лица делает моделирование человеческого лица нетривиальной задачей. 3DMM создётся для получения модели лица в пространстве явных соответствий. Это означает поточечное соответствие между полученной моделью и другими моделями, позволяющими выполнять морфирование. Кроме того, в 3DMM должны быть отражены трансформации низкого уровня, такие как отличия мужского лица от женского, нейтрального выражения лица от улыбки.
Исследователи из Университета Мичигана предлагают новейший метод получения 3DMM лица, основанный на глубоком обучении. Используя высокую эффективность глубоких нейронных сетей для осуществления нелинейных отображений, их метод позволяет получить 3DMM на основе 2D изображения, снятого в произвольной обстановке.
Используя высокую эффективность глубоких нейронных сетей для осуществления нелинейных отображений, их метод позволяет получить 3DMM на основе 2D изображения, снятого в произвольной обстановке.
Более ранние подходы
Обычно 3DMM получают с помощью набора 3D сканов лиц и набора 2D изображений этих же лиц. Общепринятый подход заключается в использовании редукции размерностей при обучении с учителем, которая выполняется с помощью применения анализа главных составляющих (Principal Component Analysis – PCA) на тренировочном наборе данных, состоящем из 3D сканов лиц и соответствующих 2D изображений. При использовании линейных моделей, таких как PCA, нелинейные трансформации и лицевые вариации не могут быть отражены в 3DMM. Более того, для моделирования точных 3D текстур лиц необходимо большое количество «3D информации». Таким образом, использование данного подхода оказывается неэффективным.
Предлагаемый метод
Идея
предлагаемого методазаключается в использовании глубоких нейронных сетей или, более конкретно,
свёрточных нейросетей (которые лучше подходят для рассматриваемой задачи и менее затратны в плане времени вычислений, чем многослойные перцептроны) для получения 3DMM.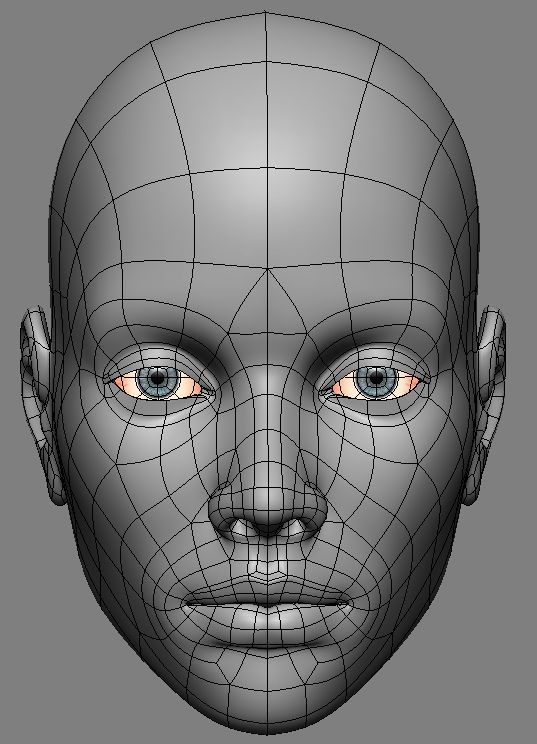
Как было указано ранее, линейная 3DMM имеет ряд проблем, таких как необходимость наличия 3D сканов лиц, невозможность использования изображений, снятых в произвольном ракурсе и ограниченная точность представления из-за использования линейной PCA. В свою очередь, предлагаемый метод позволяет получить нелинейную 3DMM модель на основе 2D изображений лиц высокого разрешения, снятых с произвольного ракурса.
Планарное представление
В своём подходе, исследователи используют развёрнутую 2D карту лица для представления его текстуры и альбедо. Они утверждают, что учёт пространственной информации играет важную роль, так как они применяют свёрточные нейронные сети, а фронтальные изображения лица содержат мало информации о боковых сторонах. Именно поэтому их выбор пал на планарное преставление.
Три различных представления альбедо. (а) – 3D представление, (в) – альбедо как 2D фронтальное изображение лица, (с) – планарное представление.
Планарное представление. x, y, z и суммарное представление текстуры.
Архитектура нейросети
Исследователи спроектировали нейросеть, которая, принимая на вход изображение, кодирует его в вектора текстуры, альбедо и освещения. Закодированные скрытые вектора для альбедо и текстуры декодируются с использованием двух декодеров, в качестве которых используются свёрточные нейросети. На выходе декодеры выдают блики лица, его альбедо и 3D текстуру лица. С использованием этих параметров, дифференцируемый рендеринг-слой генерирует модель лица посредством совмещения 3D текстуры, альбедо, освещения и параметров расположения камеры, полученных энкодером. Архитектура представлена на схеме ниже.
Архитектура предлагаемого метода для получения нелинейной 3DMM
Получаемая устойчивая нелинейная 3DMM может быть использована для 2D наложения лиц и решения проблемы трёхмерной реконструкции лиц.
Схема рендеринг-слоя
Сравнение с другими методами
Рассматриваемый метод был приведён в сравнение с другими методами на примере следующих задач:
2D наложение, 3D реконструкция и редактирование лиц. Предлагаемый метод превосходит другие современные подходы для решения этих задач. Результаты сравнения представлены ниже.
2D наложение лица
Одно из приложений метода — наложение лиц, что должно существенно улучшить анализ лиц в ряде задач (к примеру, распознавание лиц). Наложение лиц – непростая задача, но рассматриваемый метод показывает высокие результаты при её решении.
Результаты 2D наложения лиц. Невидимые пометки отмечены красным. Рассматриваемый метод отражает необычные позы, освещение и выражение лица.
3D реконструкция лица
Рассматриваемый метод также был приведён к сравнению на примере 3D реконструкции лица и показал выдающиеся результаты по сравнению с другими методами.
Количественное сравнение результатов 3D реконструкции
Результаты 3D реконструкции в сравнении с методом Sela и др. Предлагаемый метод сохраняет волосы на лице и другие особенности лица намного лучше, чем этот метод.
Предлагаемый метод сохраняет волосы на лице и другие особенности лица намного лучше, чем этот метод.
Результаты 3D реконструкции в сравнении с VRN от Jackson и др. на примере известного датасета CelebA.
Результаты 3D реконструкции в сравнении с методом Tewari и др. Как видно, предлагаемый метод решает проблему сжимания лица при наличии различных текстур (таких как волосы на лице).
Редактирование лица
Обсуждаемый метод разбивает изображение лица на отдельные элементы и позволяет изменять лицо с помощью манипуляций над ними. Результаты работы данного метода при редактировании лиц были оценены на примере таких задач, как изменение освещения и добавление дополнительных элементов лица.
Результаты добавления бороды. Первая колонка содержит исходные изображения, последующие – разные степени изменения бороды.
Сравнение с методом Shu и др. (вторая строка). Как видно, предлагаемый метод даёт более реалистичные изображения, и кроме того, лучше сохраняется идентичность лица.
Вывод
Предлагаемый метод, предположительно, получит широкое распространение, так как он позволяет получить точную и устойчивую 3DMM. Хотя 3DMM была широко распространена с момента своего создания, до появления рассматриваемого метода не существовало эффективного получения этой модели с помощью 2D изображений с произвольного ракурса.
Предлагаемый метод использует глубокие нейронные сети в качестве аппроксиматора для устойчивого моделирования человеческих лиц со всеми их особенностями. Столь необычный способ получения 3DMM позволяет проводить манипуляции с изображением и может быть использован во многих задачах, некоторые из которых были представлены статье.
Перевод — Борис Румянцев.
Ю.С.Васильев — Компьютерное моделирование пластических операций
На мой взгляд — не только очень важный, но и необходимый этап при планировании операций, связанных с изменением формы лица. Моделирование нужно не столько пациенту, сколько самому хирургу. И вот почему. Пытаясь «на пальцах» объяснить свои желания и возможности, очень часто пациент и врач не до конца понимают друг друга. Порой то, что представляет в уме каждая из сторон — абсолютно разные вещи. В результате получаем либо недовольного пациента, либо недовольного врача (такое тоже бывает: пациент доволен, а ты считаешь, что мог бы сделать лучше).
И вот почему. Пытаясь «на пальцах» объяснить свои желания и возможности, очень часто пациент и врач не до конца понимают друг друга. Порой то, что представляет в уме каждая из сторон — абсолютно разные вещи. В результате получаем либо недовольного пациента, либо недовольного врача (такое тоже бывает: пациент доволен, а ты считаешь, что мог бы сделать лучше).
В общем, моя позиция такова, что на планирование операций нужно тратить мно-о-ого времени. Даже если речь идет о банальной ринопластике, я встречаюсь с пациентом 2 или 3 раза, согласовывая все возможные варианты. Если же речь идет о более сложных вмешательствах, то на планирование и подготовку иногда приходится потратить гораздо больше времени, чем на саму операцию. Далее о том, каким образом происходит этот процесс.
Первая консультация:
Недовольны формой носа, но сомневаетесь, нужна ли Вам операция? Хотите подбородок как у известной модели и уже собрались к пластическому хирургу с распечатанным снимком «идеала» и заготовленной фразой: «Слелайте мне такой же»? Давайте это обсудим… Главное — не торопиться. На первой консультации я даже не буду слушать, чего Вы хотите. Я буду слушать, что Вас не устраивает. Потом проведу клиническое обследование, сделаю фотоснимки и спокойно посижу за компьютером, чтобы понять, что я могу предложить. А понять это я смогу только после тщательной комплексной диагностики. Ведь лицо — это не только нос или подбородок. Если обычных фотографий окажется мало, то возможно потребуется рентгенологическое исследование. Или снятие зубных оттисков. Иногда только после комплексного обследования можно поставить правильный диагноз (грубо говоря, — понять, почему лицо или какая-либо его часть выглядит так а не иначе).
На первой консультации я даже не буду слушать, чего Вы хотите. Я буду слушать, что Вас не устраивает. Потом проведу клиническое обследование, сделаю фотоснимки и спокойно посижу за компьютером, чтобы понять, что я могу предложить. А понять это я смогу только после тщательной комплексной диагностики. Ведь лицо — это не только нос или подбородок. Если обычных фотографий окажется мало, то возможно потребуется рентгенологическое исследование. Или снятие зубных оттисков. Иногда только после комплексного обследования можно поставить правильный диагноз (грубо говоря, — понять, почему лицо или какая-либо его часть выглядит так а не иначе).
|
Приведу один пример. Девушка недовольна формой носа, она считает его слишком большим. Но, на самом деле это не так. При анализе можно сказать, что имеется дисбаланс между размерами носа и подбородка. И если увеличить подбородок, то лицо станет намного лучше. При этом ринопластику можно и не делать. |

Анализ лица:
|
Анализ лица и планирование эстетических операций — это смесь науки, искусства и опыта. У меня давно зреет идея написать об этом отдельную статью или даже книгу, но пока что времени не хватает. Поэтому в этом материале все крупными мазками. На первом этапе проводится общая оценка пропорций лица. Секрет гармонии заключается в сбалансированном соразмерном расположении всех его частей. Внимание обращается не только на форму носа, но также и на его взаимоотношение с подбородком, скулами, глазами. Очень важным этапом является оценка эстетики зубов и улыбки. В некоторых случаях дается рекомендация по ортодонтическому лечению. При наличии выраженных признаков аномалий расположения зубов и челюстей проводится дополнительное рентгенологическое исследование. |

Моделирование и обсуждение:
Ну а дальше происходит непосредственно сам процесс моделирования результата операции. При помощи специальных программ я формирую новый внешний вид лица или отдельных его частей. Этот процесс в зависимости от степени сложности операции может занимать от 2-3 часов до 2-3 дней. Полученный результат обсуждается с пациентом. На этом этапе я уже более внимательно прислушиваюсь к Вашему мнению относительно желаемого результата. Практически у каждого вида операции существуют как «крайние» варианты, так и промежуточные. Если пожелания пациента выходят за эти рамки, то на этом мы расстаемся. Многие люди верят в «чудеса» пластической хирургии. А я — нет. Поэтому я не буду делать операцию, если вижу, что желаемый результат недостижим или сделает человека очередной «жертвой» пластической хирургии.
Итог:
Визуализация конечного результата операции на лице — крайне важный этап подготовки как для пациента, так и для хирурга. Возможности современной компьютерной техники позволяют сделать это с высокой долей точности (хотя и не 100%-ной). Подробное осуждение всех деталей операции создает более доверительную атмосферу и предупреждает многие вопросы и разочарования в послеоперационном периоде.
Компьютерное моделирование как услуга:
На сегодняшний день я предлагаю компьютерное моделирование при планировании следующих операций:
- ринопластика;
- отопластика;
- изменение формы подбородка;
- изменение формы скуловых дуг;
- изменение формы всего лица.
Предоперационное компьютерное моделирование внешности
- Результаты работ Результаты работ »
- Предоперационное компьютерное моделирование внешности
 org/ListItem»>
Отделение пластической хирургии
Отделение пластической хирургии
»
org/ListItem»>
Отделение пластической хирургии
Отделение пластической хирургии
»
Можно ли во всех деталях представить себе результаты пластической операции? Требуется ли для этого обладать незаурядным воображением? На эти вопросы дают наилучший ответ современные компьютерные технологии.
Сегодня мы имеем возможность наглядно продемонстрировать Вам результаты любых хирургических манипуляций. С помощью опытного пластического хирурга в нашей клинике Вы сможете создать точную визуальную модель своей будущей внешности. При этом все изменения экранного образа будут полностью соответствовать как возможностям пластической хирургии, так и анатомическим особенностям Вашего тела.
При этом все изменения экранного образа будут полностью соответствовать как возможностям пластической хирургии, так и анатомическим особенностям Вашего тела.
Мы предлагаем Вам увидеть портрет своей улучшенной внешности еще до выполнения пластической операции. В процессе моделирования Вашего нового образа хирург сможет руководствоваться не только Вашими пожеланиями, но и своим природным эстетическим чувством. Таким образом, совместно с нами Вы безошибочно создадите настоящий автопортрет своей мечты. Воплотить же его в реальность, причем самым наилучшим образом, позволит незаурядный талант наших пластических хирургов. И когда полученный образ станет неотъемлемой частью Вашей внешности, он непременно будет приносить радость как Вам самим, так и Вашим близким!
Пример предоперационного компьютерного моделирования ринопластики!
Запишитесь на консультацию к пластическому хирургу прямо сейчас
по телефонам: +7 (812) 627-13-13
Если Вы действительно ищете своего доктора. ..
..
Врачи отделения пластической хирургии
| Полный перечень услуг и их стоимость | |
| Задать вопрос | |
| Заказать обратный звонок или позвоните по тел.: +7 (812) 627-13-13 |
КОМПЬЮТЕРНОЕ МОДЕЛИРОВАНИЕ
Том 6, Выпуск №3, 2021В данной статье рассматривается совершенствование работы предприятия производственной сферы ООО «ТЭТА ФУД», которая заключается в повышении эффективности работы сотрудников предприятия за счет сокращения времени на формирование полного объема …
Том 6, Выпуск №3, 2021 В статье рассматривается построение имитационной модели абстрактного процесса преобразования сырьевых компонентов в портландцементный клинкер в среде имитационного моделирования UFOModeler. Разработан алгоритм генерации псевдослучайного оксидного (химического) состава компонентов на …
Разработан алгоритм генерации псевдослучайного оксидного (химического) состава компонентов на …
При эксплуатации объектов информатизации необходимым условием их функционирования является наличие подсистемы аутентификации. Применение многомодальных систем аутентификации на объектах информатизации сопровождается использованием методов распознавания лиц на изображении. Многообразие существующих на …
Том 4, Выпуск №4, 2019Данная статья посвящена разработке компьютерной системы, предназначенной для исследования типа лейкоза крови на основе анализа рельефа поверхности лимфоцитов на трехмерных изображениях клеток крови. Реализация алгоритма в рамках данной разработки …
Том 4, Выпуск №3, 2019 В статье исследованы свойства квазисубполосных матрицах косинус-преобразования, используемых при субполосном анализе-синтезе сигналов и изображений. Показано, что их собственные числа могут иметь положительные и отрицательные значения; предложены оценки их . ..
..
Для решения горных задач требуется построение детальных блочных или воксельных моделей, обеспечивающих оперативное планирование дискретных объёмов выемки горных пород. Перед началом проведения работ на территории предполагаемого карьера, необходимо проанализировать …
Том 4, Выпуск №2, 2019В статье рассматриваются подходы к решению проблемы точной и объективной регистрации и оценке роста и развития растений (отдельных его частей) на разных по составу питательных средах и различных …
Том 4, Выпуск №2, 2019Актуальность Классическая термодинамика как основа многих физических наук на настоящее время не обладает законченным и четким аксиоматическим построением теории. Некоторые из ее положений и соотношений базируются …
Том 4, Выпуск №1, 2019 В работе предложен оригинальный ортонормированный базис, составленный из собственных векторов субполосных матриц косинус-преобразования, соответствующих заданной подобласти области определения косинус-преобразования. Показано разложение цифровых изображений по векторам предложенного базиса. Введено …
Показано разложение цифровых изображений по векторам предложенного базиса. Введено …
В данной статье рассматривается эвристический алгоритм сегментации облака точек, описывающего предмет интерьера, с целью получения сегментации, близкой к разбиению объекта на функциональные элементы. Данный алгоритм применяется как часть метода улучшения …
Том 3, Выпуск №3, 2018В геоинформационных системах недропользования применяется широкий комплекс вычислительных методов создания полигональных и воксельных моделей, включающий методы геостатистики, триангуляции, интерполяции и оптимизации границ извлечения запасов. Для решения горных задач …
Том 3, Выпуск №2, 2018 В работе уточняется определение системы в терминах системно-объектного подхода «Узел-Функция-Объект», основанного на исчислении объектов Абади-Кардели, предложена формализация понятий «системообразующий фактор» и «адаптация системы». Представленные формализмы использованы для учета общесистемных . ..
..
Данная статья посвящена реализации основных возможностей графического интерфейса OpenGL при построении сетки рассеивания выбросов вредных веществ в атмосферу дорожно-строительной техникой, отмечена актуальность применения и основные преимущества библиотеки OpenGL относительно других графических интерфейсов. В …
Том 3, Выпуск №1, 2018В статье рассматривается применение модели знаний о динамике распространения подземных вод на примере Ильинского водозабора. Показано изменение уровня подземных вод в зависимости от увеличения количества откачиваемой воды, изменение уровня …
Том 2, Выпуск №4, 2017Сегодня строительство жилых комплексов является одним из приоритетных направлений быстроразвивающихся регионов Российской Федерации, в особенности, следует отметить индивидуальное жилищное строительство. В результате образовываются и интенсивно развиваются особые составляющие …
Том 2, Выпуск №3, 2017 Рассмотрен подход, реализованный в разработанной математической модели системы многомодальной аутентификации пользователя, получения оценки условных вероятностей байесовской сети доверия на основе использования нечисловой экспертной, неточной и неполной информации о . ..
..
В работе рассматриваются основные аспекты системно-объектного имитационного моделирования систем массового обслуживания с применением программного средства UFOModeler. Приводится классическое понимание системы массового обслуживания, рассматриваются варианты формального построения моделей. Основная …
Том 1, Выпуск №4, 2016В статье представлено сравнение чувствительности некоторых мер различия между исходным сигналом и сигналом, полученным в результате добавления дополнительной информации. Сравнение основано на анализе результата реализации стеганографического метода расширения …
Том 1, Выпуск №4, 2016 В работе средствами инволютивных распределений геометрической теории управления получена работоспособная линейная математическая модель движения дизель-поезда с двумя эквивалентными тяговыми электроприводами, которая эквивалентна нелинейной математической модели, описываемой системой нелинейных . ..
..
Сегментация является сложным этапом в обработке и анализе медицинских изображений. Это связано с высокой вариабельностью их характеристик, слабой контрастностью обрабатываемых изображений и сложной геометрической организацией объектов. Рассмотрена реализация …
Пластика, меняющая жизнь | Клиника «Золотое Сечение»
Олег Михайлович Михайлов заведующий отделением пластической хирургии клиники «Золотое Cечение», внештатный специалист Министерства здравоохранения Новосибирской области по пластической хирургии:
«Пластическая хирургия — это огромный раздел медицины, включающий в себя не только эстетическую хирургию, но и реконструктивные операции для физической и социальной адаптации человека в обществе. Поэтому «Золотое Сечение» вышло за рамки формата моноклиники эстетической медицины и сейчас активно развивается в направлении многопрофильного медицинского центра, в котором вместе с пластическими хирургами будут работать травматологи, гинекологи, сосудистые хирурги, оториноларингологи, онкологи, косметологи, физиотерапевты и другие узкие специалисты.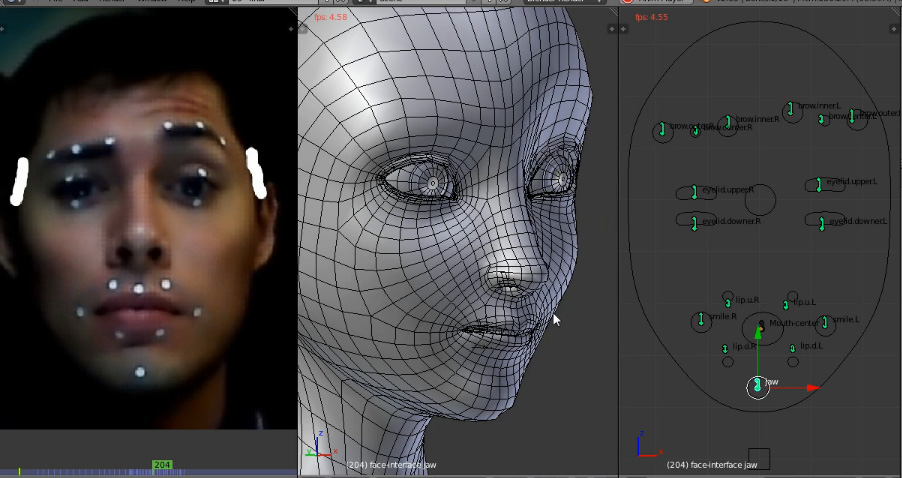 Таким образом, мы сможем совмещать эстетическую коррекцию носа с восстановлением носового дыхания, маммопластику — с удалением различных образований молочной железы, абдоминопластику — с удалением грыжи и так далее. При этом работать с пациентом будет не один хирург, который — как бы талантлив он ни был — не может делать все одинаково хорошо, а команда специалистов, где каждый в совершенстве знает свое направление и несет за него ответственность.
Таким образом, мы сможем совмещать эстетическую коррекцию носа с восстановлением носового дыхания, маммопластику — с удалением различных образований молочной железы, абдоминопластику — с удалением грыжи и так далее. При этом работать с пациентом будет не один хирург, который — как бы талантлив он ни был — не может делать все одинаково хорошо, а команда специалистов, где каждый в совершенстве знает свое направление и несет за него ответственность.
Такие операции, которые в хирургии называют «симультанными», мы уже проводим в нашей клинике — например, у нас полностью отработана комплексная технология ринопластики. Если в мировой бьюти-индустрии процент повторных операций носа достигает 36%, то у нас эта цифра существенно меньше, так как в «Золотом Сечении» над формой, анатомией носа и восстановлением кожи после ринопластики работает целая команда специалистов. При таком подходе наши пациенты обретают гармонию черт лица и свободу дыхания — всего за одну операцию!
ТЕХНОЛОГИЯ РИНОПЛАСТИКИ В КЛИНИКЕ «ЗОЛОТОЕ СЕЧЕНИЕ» ВКЛЮЧАЕТ СЛЕДУЮЩИЕ ЭТАПЫ:
• первичная консультация хирурга, в процессе которой мы выясняем пожелания пациента, даем свои рекомендации и назначаем обследование, чтобы выяснить, есть ли у пациента сопутствующие патологии. Уже на этом этапе мы можем провести компьютерное моделирование лица и показать пациенту возможные варианты его будущего носа. После этого пациент решает, согласен он на операцию или нет;
Уже на этом этапе мы можем провести компьютерное моделирование лица и показать пациенту возможные варианты его будущего носа. После этого пациент решает, согласен он на операцию или нет;
• повторная консультация, на которую мы, исходя из результатов обследования, можем пригласить других специалистов: терапевта, оториноларинголога, анестезиолога, косметолога — чтобы совместно составить план операции;
• заключительная консультация перед операцией, на которой мы утверждаем план лечения, знакомим пациента с возможными рисками, подробно проговариваем особенности реабилитационного периода. После этого пациент подписывает информированное согласие, прилагающееся к договору. Однако это вовсе не значит, что клиника снимает с себя ответственность за исход операции. Наоборот — мы несем полную ответственность за пациента и, если результат операции не удовлетворяет, проводим коррекцию;
• операция. Клиника «Золотое Сечение» располагает полноценным операционным блоком с операционной, перевязочной и стационаром — все оборудовано в соответствии с нормативами СанПиН. Благодаря современной системе вентиляции, воздух, поступающий в операционную, проходит четыре ступени очистки, обеспечивая абсолютную стерильность. Операционная укомплектована самой современной аппаратурой, которая отслеживает все показатели жизни, а также — реанимационным оборудованием. С первой до последней минуты на операции присутствует анестезиолог-реаниматолог, который контролирует состояние пациента;
Благодаря современной системе вентиляции, воздух, поступающий в операционную, проходит четыре ступени очистки, обеспечивая абсолютную стерильность. Операционная укомплектована самой современной аппаратурой, которая отслеживает все показатели жизни, а также — реанимационным оборудованием. С первой до последней минуты на операции присутствует анестезиолог-реаниматолог, который контролирует состояние пациента;
• реабилитация. В первые же часы после операции с пациентом начинает работать косметолог, направляя процесс восстановления тканей в нужное русло. Физиотерапия в последующие несколько недель помогает правильному формированию рубцов. В клинике «Золотое Сечение» мощнейшая косметология, поэтому, как правило, реабилитация пациентов проходит быстро и комфортно. Однако я всегда предупреждаю, что конечный результат ринопластики при соблюдении всех рекомендаций врача необходимо оценивать в срок от одного года до трех лет.
Я всегда говорю, что формула успешной операции — это 50% таланта хирурга и 50% грамотной работы всей операционной бригады. Я рад, что в клинике «Золотое Сечение» нам удалось воплотить комплексный подход к пластической хирургии. Мне нравится атмосфера, сложившаяся в нашей команде, которой движет желание не зарабатывать на пациентах, а помогать им обрести красоту, здоровье, уверенность в себе, а иногда — и долгожданное счастье. Для меня это дороже любых денег.»
Я рад, что в клинике «Золотое Сечение» нам удалось воплотить комплексный подход к пластической хирургии. Мне нравится атмосфера, сложившаяся в нашей команде, которой движет желание не зарабатывать на пациентах, а помогать им обрести красоту, здоровье, уверенность в себе, а иногда — и долгожданное счастье. Для меня это дороже любых денег.»
Мария Александровна Калинина, анестезиолог-реаниматолог:
«Один из самых главных страхов пациентов перед операцией — «уснуть и не проснуться».
При планировании оперативного вмешательства используем индивидуальный подход в выборе метода анестезиологического пособия, на основании всестороннего обследования и тщательного сбора анамнеза.
Поэтому мы всегда применяем наиболее безопасную, адекватную и комфортную тактику проведения наркоза. По желанию пациента медикаментозным способом снижаем степень тревоги, добавляя в премедикацию препараты, дающие от легкого успокоительного эффекта до состояния, при котором человек даже не помнит, как он попал в операционную.
Современные наркозно-дыхательные аппараты в комплексе с контрольно-следящим оборудованием позволяют на протяжении всего оперативного вмешательства в полной мере контролировать глубину наркоза, адекватность анестезии и все жизненно-важные показатели пациента.
Во избежание аллергических реакций используются только оригинальные лекарственные препараты, с минимальным токсическим действием на организм пациента.
По окончании операции пациент плавно просыпается, а все лекарственные препараты бесследно выводятся из организма.»
Людмила Петровна Семенова, врач-дерматолог, косметолог, сертифицированный специалист по лазерным технологиям:
«Реабилитация пациента после ринопластики начинается уже в хирургическом отделении. В течение первых суток после операции можно проводить локальную криотерапию, это воздействие смеси азота с воздухом. Процедура оказывает охлаждающее, противовоспалительное действие, уменьшает отек. С третьего-четвертого дня мы подключаем биокибернетическую микротоковую терапию на аппарате «Бьюти-тек». Микротоки выравнивают мембранный потенциал клеток и дают мощный лимфодренажный эффект. Вместе с косметологами в клинике «Золотое Сечение» работает опытный физиотерапевт. В команде с ним и с нашими хирургами мы решаем свою главную задачу – чтобы вы получили новое лицо, красивую и здоровую кожу.»
Микротоки выравнивают мембранный потенциал клеток и дают мощный лимфодренажный эффект. Вместе с косметологами в клинике «Золотое Сечение» работает опытный физиотерапевт. В команде с ним и с нашими хирургами мы решаем свою главную задачу – чтобы вы получили новое лицо, красивую и здоровую кожу.»
http://style-journal.com/archive/2017/6/plastika,-myenyayushchaya-zhizn.html
5 модных способов укрыться от идентификации лица (и напугать прохожих)
Сегодня алгоритм распознавания лиц используется везде. И не только в профессиональных системах слежения или умных веб-сервисах, но в разных развлекательных приложениях и базовых функциях вроде автофокуса. «Афиша Daily» решила попытаться обмануть алгоритм при помощи макияжа.
Разные системы распознавания человеческого лица имеют различные цели, поэтому и алгоритмы их отличаются. Одни из первых систем, которые были способны установить личность человека по фото, искали на изображении узловые точки, составляющие основные черты лица, и мерили между ними расстояния. Основные параметры измерений — это расстояние между глазами, ширина носа, глубина глазницы, форма скул, длина линии челюсти. Ключевые показатели в цифровом выражении составляли уникальный код или фейспринт, представляющий человека в базе данных. Так для установления личности подозреваемого его фото загружается в систему, а фейспринт сверяется с тысячами других аналогичных.
Одни из первых систем, которые были способны установить личность человека по фото, искали на изображении узловые точки, составляющие основные черты лица, и мерили между ними расстояния. Основные параметры измерений — это расстояние между глазами, ширина носа, глубина глазницы, форма скул, длина линии челюсти. Ключевые показатели в цифровом выражении составляли уникальный код или фейспринт, представляющий человека в базе данных. Так для установления личности подозреваемого его фото загружается в систему, а фейспринт сверяется с тысячами других аналогичных.
Проблема метода в том, что при разных углах съемки, освещении и даже выражении лица измеряемые показатели могут изменяться. Поэтому более современные программы используют 3D-моделирование лиц, что дает более точные результаты. Анализируя на фотографии участки лица, где более явны жесткие ткани и кости — глазницы, нос, подбородок (эти области уникальны и не изменяются с течением времени), программа выстраивает трехмерную модель лица и после этого уже «разворачивает» модель как угодно — в профиль или анфас, параллельно измеряет черты лица на субмиллиметровом масштабе.
Но и этот метод не идеален — для 100%-ного результата желательно проверить и идентифицировать несколько фото.
Для самых точных на сегодня показателей используются биометрические алгоритмы, анализирующие уникальные текстуры кожи, радужки глаза или даже рисунка вен.
Процесс анализа текстуры поверхности работает по сути как и распознавание лиц. Изображение человека (например, его лица) разбивается на более мелкие блоки, а алгоритмы различают на текстуре и радужке глаза мельчайшие линии, морщинки, поры, родинки и даже структуру кожи — все это предстает в виде математической модели. Благодаря этой системе легко определить различия даже между идентичными близнецами.
Самые простые алгоритмы анализа лиц — те, которые используются в развлекательных приложениях вроде Snapchat, а также в фотопрограммах, где фокус автоматически наводится на лицо. Эти программы анализируют овал лица, а также положение основных черт лица — глаз, носа, рта.
Эти программы анализируют овал лица, а также положение основных черт лица — глаз, носа, рта.
Подробности по теме
8 средств для киберпараноиков вместо шапочки из фольги
8 средств для киберпараноиков вместо шапочки из фольгиКак работает мейкап-камуфляж
Самый первый этап распознавания лица в любой системе — это обнаружение лица на изображении. Когда программа лица не видит, то ей нет смысла ни анализировать черты лица, ни подсчитывать расстояния между ключевыми точками. Так что логично блокировать систему именно на этом этапе. Поиск лица в кадре работает по довольно простому алгоритму, который анализирует наличие овала лица, глаз, носа и рта. Однако с помощью нехитрого набора косметики паттерны лица можно разбивать, заставив машину думать — это может быть чем угодно, но не лицом.
5 главных принципов мейкап-камуфляжа
К сожалению, рисунки на лице не помогут укрыться от идентификатора. Просто картина на лице, даже если она выполнена не в классической цветовой гамме, все равно обречена на ушки собачки из Snapchat. Первое, по чему ориентируется идентификатор, — это овал лица, уши и нос. Тут сможет помочь только скотч, который поменяет очертания полностью. Приклейте нос к щеке, а уши сверните в трубочки, распределите макияж, используйте необычные тона и приемы, чтобы не было особой разницы между цветом глаз, щек и губ. Не стоит подчеркивать глаза или скулы — это, наоборот, упростит распознавание лица для системы.
Просто картина на лице, даже если она выполнена не в классической цветовой гамме, все равно обречена на ушки собачки из Snapchat. Первое, по чему ориентируется идентификатор, — это овал лица, уши и нос. Тут сможет помочь только скотч, который поменяет очертания полностью. Приклейте нос к щеке, а уши сверните в трубочки, распределите макияж, используйте необычные тона и приемы, чтобы не было особой разницы между цветом глаз, щек и губ. Не стоит подчеркивать глаза или скулы — это, наоборот, упростит распознавание лица для системы.
Два симметричных глаза — явный признак лица для компьютерного зрения. Постарайтесь скрыть оба глаза или хотя бы один из них. Лучше всего использовать материалы, которые рефлектируют свет — блестки, кусочки зеркала или полностью гладкие, отражающие свет поверхности. Блики отвлекут систему от естественных лицевых теней и не дадут распознать лицо.
Попробуйте поиграть с эллиптической формой головы и симметрией ушей. К сожалению, это помогает не всегда, так как система распознает овальную форму и, если находит на ней тени от век или носа, то срабатывает. Область, где находятся нос, глаза и лоб, — ключевая для системы распознавания лица. Попробуйте разбить этот треугольник, нанеся на переносицу неожиданный элемент, например, яркую краску (в нашем случае желтую).
К сожалению, это помогает не всегда, так как система распознает овальную форму и, если находит на ней тени от век или носа, то срабатывает. Область, где находятся нос, глаза и лоб, — ключевая для системы распознавания лица. Попробуйте разбить этот треугольник, нанеся на переносицу неожиданный элемент, например, яркую краску (в нашем случае желтую).
Изменяйте контрастные тональные градиенты, меняйте пространственное соотношение темных и светлых областей лица, используя макияж, аксессуары и свои волосы. Неожиданно торчащие завитые пряди не натурального цвета (а лучше нескольких цветов) и изменение фактуры кожи, сценический грим, ощущение расплавленного лица и отсутствие цветовой фокусировки на основных деталях лица (глаза, нос, губы) также сделают свое дело — если вы подведете камеру телефона к этой картинке, то лицо опознано не будет, хотя абсолютно понятно, что на фото человек.
Постарайтесь максимально разбавить симметрию между левой и правой половинами лица, например, с помощью волос. Когда область глаза закрыта, а на другую сторону нанесена краска, не выделяющая глаза или губы, а контрастными пятнами, это меняет общее строение лица — и камера уже не распознает очертание головы. Идентификатор определит волосы по однородности их цвета и фактуры — используйте бусины или положите в волосы пушистые комочки ваты, это убьет ощущение челки, и идентификатор не сработает.
Когда область глаза закрыта, а на другую сторону нанесена краска, не выделяющая глаза или губы, а контрастными пятнами, это меняет общее строение лица — и камера уже не распознает очертание головы. Идентификатор определит волосы по однородности их цвета и фактуры — используйте бусины или положите в волосы пушистые комочки ваты, это убьет ощущение челки, и идентификатор не сработает.
Все видео сняты на телефон Huawei P9 c двойной камерой Leica 12 МП + 12 МП
Подробности по теме
Как быстро сделать необычный макияж на Хеллоуин
Как быстро сделать необычный макияж на ХеллоуинРеконструкция внешности 30 000-летних Homo sapiens
30 000 лет назад на территории Владимирской области располагался сезонный охотничий лагерь Сунгирь. Этот лагерь — самое северное палеолитическое поселение ранних Homo sapiens в Европе. В суровых условиях ледникового периода жители Сунгиря развили ремесленное мастерство до высокого уровня и оставили после себя более 80 000 предметов быта и культуры. Считается, что сунгирцы — возможные предки нынешних восточных и северных европейцев.
Этот лагерь — самое северное палеолитическое поселение ранних Homo sapiens в Европе. В суровых условиях ледникового периода жители Сунгиря развили ремесленное мастерство до высокого уровня и оставили после себя более 80 000 предметов быта и культуры. Считается, что сунгирцы — возможные предки нынешних восточных и северных европейцев.
Студия Visual Science и Институт этнологии и антропологии РАН при поддержке «Всероссийского Фестиваля науки «Nauka 0+» создали реконструкцию внешности людей Сунгиря в формате 3D VR-анимации. Научно достоверная визуализация выполнена на основе черепов двух детей 10 и 13 лет, захороненных в поселении, и предыдущих реконструкциях внешности сунгирцев.
Visual Science предоставляет музеям и школам бесплатный доступ к VR-анимации Сунгиря через мобильное приложение VRScience, совместимое с VR-очками Google Cardboard и другими VR-устройствами, поддерживающими разрешение 4K.
Реконструкция внешности 10-летнего ребенка из Сунгиря в формате 3D
Реконструкция внешности 13-летнего ребенка из Сунгиря в формате 3D
Компьютерное моделирование внешности жителей Сунгиря проводилось с применением технологий реконструкции лиц, а также на основании данных лазерного сканирования и высокоточной фотосъемки черепов из захоронения. VR-анимация показывает процесс реконструкции и визуализации слой за слоем: от разметки отдельных реперных точек на черепе и наложения мягких тканей головы до появления финального анимированного портрета.
VR-анимация показывает процесс реконструкции и визуализации слой за слоем: от разметки отдельных реперных точек на черепе и наложения мягких тканей головы до появления финального анимированного портрета.
Мне нравится VR-анимация «Сунгирь», потому что она сделана с высокой точностью и вниманием к деталям. Физиогномические черты детей, показанные в визуализации, напоминают черты черепа из останков Дольни-Вестонице 15, найденных в верхнепалеолитическом поселении в Чехии
— профессор Йиржи Свобода, доктор исторических наук, руководитель Центра изучения палеолита и палеоантропологии в Институте археологии Чешской академии наук.
В качестве базы для компьютерного моделирования были взяты скульптурные визуализации детей из Сунгиря, созданной по методике ученого Михаила Герасимова.
Метод антропологической реконструкции Герасимова
В середине XX века Михаил Герасимов создал первый научно обоснованный метод антропологической реконструкции лица человека по черепу. Он был основан на представлении о том, что существует соподчиненность формы лицевого скелета и элементов внешности. Применяемые Герасимовым анатомический и рентгенографический методы позволили не только разработать эталоны толщины мягких тканей по линии профиля, но и обнаружить закономерность в распределении толщины этих тканей в зависимости от степени развития рельефа черепа. Строение отдельных деталей лица определялось индивидуальными морфологическими особенностями черепа. Ученики Герасимова разработали техники восстановления носа и ушей.
Он был основан на представлении о том, что существует соподчиненность формы лицевого скелета и элементов внешности. Применяемые Герасимовым анатомический и рентгенографический методы позволили не только разработать эталоны толщины мягких тканей по линии профиля, но и обнаружить закономерность в распределении толщины этих тканей в зависимости от степени развития рельефа черепа. Строение отдельных деталей лица определялось индивидуальными морфологическими особенностями черепа. Ученики Герасимова разработали техники восстановления носа и ушей.
Степень приближения реконструкции к подлинности была проверена целым рядом работ по восстановлению лиц современных людей, прижизненное изображение которых сохранилось. Методика была апробирована главным образом на криминалистическом материале.
Метод Герасимова до сих пор применяется в России, Европе и США. В последнее время проводить реконструкцию стало проще благодаря появлению ультразвукового сканирования и томографии.
Стадии 3D-визуализации: расстановка реперных точек на черепе.

Стадии 3D-визуализации: наложение мягких тканей и получение «ожившего» 3D-портрета.

Популяризация знаний о Сунгире
Археологи начали раскопки Сунгиря в 1956 году. Изучение сунгирских находок в течение последних 60 лет позволило накопить значительный объем антропологических данных, тем самым уточнив наши представления об эволюции человека и расселении представителей Homo sapiens по территории Европы. Кроме того, найденные артефакты углубили знания ученых об инструментах, которыми владели люди 30 тысяч лет назад. Современные техники визуализации, которые Visual Science использовала в работе, дали возможность восстановить даже мельчайшие исторические детали и представить научные данные о Сунгире в формате, который понятен широкой аудитории.
Создание реалистичных человеческих лиц в компьютерной 3D-графике для фильмов и видеоигр: новый метод для художников, простой и мощный
Зачастую чудовища, инопланетяне и животные в фильмах и видеоиграх обладают поразительно человеческими чертами лица и выражениями.
В прошлом работа по рендерингу реалистичных анимированных лиц была в лучшем случае кропотливой. Теперь последние достижения в области анимации значительно сокращают время, затрачиваемое на создание персонажей.
«В развлекательных приложениях, таких как фильмы и игры, модели человеческого лица часто должны создаваться художниками, а не с использованием автоматизированного метода.Например, многие персонажи анимационных фильмов и игр являются вымышленными, поэтому их нельзя отсканировать. Таким образом, существует потребность в методе дизайна лица, который был бы одновременно простым, понятным и мощным для художников. Мы представляем систему, которая элегантно удовлетворяет эту потребность», — пишут Сын-Хён Юн, Джон Льюис и Тэхён Ри, авторы книги «Смешивание деталей лица: синтез лица с использованием многомасштабных моделей лица» (для доступа к полному тексту требуется вход в систему). выпуск журнала IEEE Computer Graphics and Applications за ноябрь/декабрь 2017 г.
Как начинается процесс
Используя эту систему, художники-аниматоры могут брать черты человеческого лица и применять их к монстру или животному.
Большая часть задачи заключается в захвате определенных черт человеческого лица и переносе их на лицо анимированного персонажа.
«Метод, использующий существующие модели лиц, может сэкономить много усилий. Смешение форм — это особенно простой, но мощный подход, широко распространенный в лицевой анимации для создания произвольных выражений», — говорят авторы.
Другие исследователи «использовали смешивание форм в качестве альтернативного инструмента для синтеза новой модели лица из существующих лиц. Они отделяют значимые области лица (такие как глаза, нос и рот) от разных лиц и пространственно собирают их в новое лицо. Их метод требует вершинного соответствия по каждой грани и ее блендшейпам», — добавили они.
Что делает эту новую систему уникальной?
«Мы представляем новую схему смешивания форм для синтеза новой модели лица с использованием взвешенного смешивания пространственных деталей из различных моделей лица. Наши многомасштабные модели лиц полностью соответствуют общему пространству параметров, где художник может интерактивно определять семантические соответствия между лицами и масштабами», — говорят авторы.
Наши многомасштабные модели лиц полностью соответствуют общему пространству параметров, где художник может интерактивно определять семантические соответствия между лицами и масштабами», — говорят авторы.
На рисунках 2-7 ниже показаны результаты аппроксимации модели 1-го забоя на разных уровнях.
Получение подробностей
Художники используют многомасштабную настройку модели лица, которая обеспечивает большую гибкость для точной настройки с помощью скалярных карт.
Создание кривых
«Построив эффективную структуру данных, такую как дерево квадрантов, для параметризации, мы можем интерактивно визуализировать 3D-кривые на 3D-модели лица, соответствующие 2D-кривым признаков в пространстве параметров.Это обеспечивает интуитивно понятные элементы управления для редактирования 3D-кривых в пространстве 2D-параметров», — говорят авторы.
Работа с 15 моделями
Система может интерактивно смешивать многомасштабные модели лица без дополнительного аппаратного ускорения.
«Поскольку мы использовали 15 граней, состоящих из базовой поверхности и четырехмасштабных CDM, у нас есть 15 + 15 × 4-мерное пространство блендшейпа; общее количество блендшейпов может быть ограничено художником», — говорят авторы.
А вот и слияние
На четырех больших гранях внизу показаны примеры синтезированных моделей граней с использованием взвешенного смешивания трех мультимасштабных моделей граней.
Смешивание многомасштабных нечеловеческих лиц
Дизайнеры переносят детали морды монстра на человеческое лицо, инопланетного лица на человеческое лицо и человеческие лица на морду броненосца.
«Наш метод не ограничивается человеческими лицами. Передача деталей между скульптурными нечеловеческими существами и лицом актера-человека — важная задача в визуальных эффектах», — говорят авторы.
Кролик с человеческим лицом
Даже кролик антропоморфизирован.
Эта модель кролика показывает детали, перенесенные из многомасштабных моделей лица человека или MFM.
Давайте пошагово.
Первое, или изображение (а), представляет собой модель кролика из Стэнфорда, обычно используемую в компьютерной графике. Затем в (б) художники перенесли детали с лиц моделей. Вот (c) семантическое значение неоднозначного лица и (d) интуитивно понятный пользовательский интерфейс в пространстве параметров 2D.
Тогда та-да! Вот результат лицевой анимации на последнем изображении (e).
«Многомасштабное смешивание граней вместе с элементами управления кривыми характеристик в пространстве параметров обеспечивает практическое решение для переноса деталей лица на абстрактное лицо. Например, такие области лица, как глаза, нос и рот на модели кролика из Стэнфорда, несколько неоднозначны», — пишут авторы.
Насколько хорошо работала система?
Авторы провели опрос 10 художников-аниматоров, которым дали 10 минут на выполнение ряда заданий.После этого их спросили, могут ли они синтезировать новое лицо и был ли новый метод моделирования простым и интуитивно понятным.
По шкале от 1 до 5 средний балл по обоим вопросам составил 4.
В конечном счете, их цель — облегчить работу художников-аниматоров. И похоже, что исследователи уже на пути к этому.
«Для интерактивной обработки неоднозначных и нечеловеческих лиц мы фокусируемся на элементах управления художником, а не формулируем проблему оптимизации, которая может работать медленно и время от времени давать сбои.Однако наш метод не запрещает добавить такой шаг. Компромисс между интерактивным семантическим контролем и автоматической оптимизацией был бы хорошим предметом для обсуждения. Решение, удовлетворяющее обеим целям, было бы идеальным и остается для дальнейшего изучения», — говорят они.
Исследования, связанные с компьютерной анимацией, в цифровой библиотеке Computer Society
Логин может потребоваться для полного текста.
О Лори Кэмерон
Лори Кэмерон является старшим автором компьютерного общества IEEE и в настоящее время пишет статьи для журналов Computer , Computing Edge и веб-сайтов Computing Now и Magazine Roundup. Свяжитесь с ней по адресу [email protected]. Подпишитесь на нее в LinkedIn.
Свяжитесь с ней по адресу [email protected]. Подпишитесь на нее в LinkedIn.
ученых-компьютерщиков создали самую точную цифровую модель человеческого лица. Вот что он может сделать | Наука
Если вы использовали приложение для смартфона Snapchat, возможно, вы превратили свою фотографию в диско-медведя или слили свое лицо с чьим-то другим лицом. Теперь группа исследователей создала самую передовую технику для создания 3D-моделей лица на компьютере. Система может улучшить персонализированные аватары в видеоиграх, распознавание лиц для обеспечения безопасности и, конечно же, фильтры Snapchat.
Когда компьютеры обрабатывают лица, они иногда полагаются на так называемую трехмерную трансформируемую модель (3DMM). Модель представляет среднее лицо, но также содержит информацию об общих закономерностях отклонения от этого среднего. Например, если у вас длинный нос, у вас, скорее всего, будет и длинный подбородок. С учетом таких корреляций компьютер может затем охарактеризовать ваше уникальное лицо, не сохраняя каждую точку на 3D-скане, а перечисляя всего пару сотен чисел, описывающих ваше отклонение от среднего лица, включая параметры, которые примерно соответствуют возрасту, полу и длине тела. лица.
лица.
Однако есть одна загвоздка. Чтобы учесть все способы изменения лиц, 3DMM должен интегрировать информацию о многих лицах. До сих пор для этого требовалось сканировать множество людей, а затем кропотливо маркировать все их характеристики. Следовательно, современные лучшие модели основаны всего на паре сотен человек, в основном белых взрослых, и имеют ограниченные возможности для моделирования людей разных возрастов и рас.
Теперь Джеймс Бут, ученый-компьютерщик из Имперского колледжа Лондона (ICL), и его коллеги разработали новый метод, который автоматизирует создание 3DMM и позволяет им включать в себя более широкий спектр человечества.Метод имеет три основных этапа. Во-первых, алгоритм автоматически определяет ориентиры на сканах лица, помечая кончик носа и другие точки. Во-вторых, другой алгоритм выстраивает все сканы в соответствии с их ориентирами и объединяет их в модель. В-третьих, алгоритм обнаруживает и удаляет плохие сканы.
«Действительно большой вклад в эту работу в том, что они показали, как полностью автоматизировать этот процесс», — говорит Уильям Смит, изучающий компьютерное зрение в Йоркском университете в Соединенном Королевстве и не участвовавший в исследовании. Маркировка десятков черт лица на многих лицах «довольно утомительна», — говорит Алан Брантон, специалист по информатике из Фраунгоферовского института исследований компьютерной графики в Дармштадте, Германия, который также не участвовал в этом. «Вы думаете, что щелкнуть точку относительно легко, но не всегда очевидно, где на самом деле находится угол рта, поэтому даже когда вы делаете это вручную, у вас есть некоторая ошибка».
Маркировка десятков черт лица на многих лицах «довольно утомительна», — говорит Алан Брантон, специалист по информатике из Фраунгоферовского института исследований компьютерной графики в Дармштадте, Германия, который также не участвовал в этом. «Вы думаете, что щелкнуть точку относительно легко, но не всегда очевидно, где на самом деле находится угол рта, поэтому даже когда вы делаете это вручную, у вас есть некоторая ошибка».
Но Бут и его коллеги на этом не остановились. Они применили свой метод к набору из почти 10 000 демографически разнообразных сканов лица.Сканирование было сделано в музее науки в Лондоне пластическими хирургами Алланом Понниа и Дэвидом Данауэем, которые надеялись улучшить реконструктивную хирургию. Они обратились к Стефаносу Зафириу, компьютерному специалисту из ICL, за помощью в анализе данных. Применение алгоритма к этим сканам создало то, что они называют «крупномасштабной моделью лица» или LSFM. В тестах с существующими моделями LSFM намного точнее представлял лица, сообщают авторы в следующем выпуске International Journal of Computer Vision . В одном сравнении они создали модель лица ребенка по фотографии. Используя LSFM, модель выглядела как ребенок. Используя одну из самых популярных существующих трансформируемых моделей, полностью основанную на взрослых, он выглядел как неродственный взрослый. У Бута и его коллег было достаточно сканирований, чтобы создать более конкретные трансформируемые модели для разных рас и возрастов. И их модель может автоматически классифицировать лица по возрастным группам в зависимости от формы.
В одном сравнении они создали модель лица ребенка по фотографии. Используя LSFM, модель выглядела как ребенок. Используя одну из самых популярных существующих трансформируемых моделей, полностью основанную на взрослых, он выглядел как неродственный взрослый. У Бута и его коллег было достаточно сканирований, чтобы создать более конкретные трансформируемые модели для разных рас и возрастов. И их модель может автоматически классифицировать лица по возрастным группам в зависимости от формы.
Команда Бута уже запустила новую модель.В другой статье исследователи используют 100 000 лиц, синтезированных их LSFM, для обучения программы искусственного интеллекта преобразованию случайных 2D-снимков в точные 3D-модели. Этот метод можно использовать для просмотра того, как подозреваемый в совершении преступления, пойманный на камеру, будет выглядеть под другим углом или на 20 лет старше. Можно было также конкретизировать и оживить исторические фигуры из портретов.
LSFM скоро может найти применение и в медицине. Если кто-то потерял нос, технология может помочь пластическим хирургам определить, как должен выглядеть новый нос, учитывая остальную часть лица.Сканирование лица также использовалось для выявления возможных генетических заболеваний, таких как синдром Вильямса, состояние, связанное с проблемами с сердцем, задержкой развития и чертами лица, такими как короткий нос и широкий рот. Более совершенная модель лиц и их вариации могли бы повысить чувствительность таких тестов. Новая модель «открывает еще несколько дверей», говорит Понния.
Если кто-то потерял нос, технология может помочь пластическим хирургам определить, как должен выглядеть новый нос, учитывая остальную часть лица.Сканирование лица также использовалось для выявления возможных генетических заболеваний, таких как синдром Вильямса, состояние, связанное с проблемами с сердцем, задержкой развития и чертами лица, такими как короткий нос и широкий рот. Более совершенная модель лиц и их вариации могли бы повысить чувствительность таких тестов. Новая модель «открывает еще несколько дверей», говорит Понния.
Следующим шагом является включение в модели выражений лица, что позволит распознавать лица в любой форме гримасы или ухмылки.Зафеириу говорит, что в настоящее время они вернулись в музей и сканируют новых посетителей.
Компьютерная модель обработки лица может показать, как мозг так быстро воспроизводит детализированные визуальные образы
Когнитивные ученые из Массачусетского технологического института разработали компьютерную модель распознавания лиц, которая выполняет серию вычислений, обратных шагам, которые программа компьютерной графики использовала бы для создания 2D-представления лица. Когнитивные ученые из Массачусетского технологического института разработали компьютерную модель распознавания лиц, которая выполняет серию вычислений, обратных шагам, которые программа компьютерной графики использовала бы для создания 2D-представления лица. 1 кредит
Когнитивные ученые из Массачусетского технологического института разработали компьютерную модель распознавания лиц, которая выполняет серию вычислений, обратных шагам, которые программа компьютерной графики использовала бы для создания 2D-представления лица. 1 кредитКогда мы открываем глаза, мы сразу видим окружающее в мельчайших деталях. Как мозг способен так быстро формировать столь детализированные представления о мире, является одной из самых больших нерешенных загадок в изучении зрения.
Ученые, изучающие мозг, пытались воспроизвести это явление с помощью компьютерных моделей зрения, но пока ведущие модели выполняют гораздо более простые задачи, такие как выделение объекта или лица на загроможденном фоне.Теперь команда ученых из Массачусетского технологического института создала компьютерную модель, которая фиксирует способность зрительной системы человека быстро генерировать подробное описание сцены из изображения и дает некоторое представление о том, как мозг достигает этого.
«В этой работе мы пытались объяснить, как восприятие может быть намного богаче, чем просто прикрепление семантических меток к частям изображения, и исследовать вопрос о том, как мы видим весь физический мир», — говорит Джош Тененбаум, профессор вычислительной когнитивной науки и член Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института (CSAIL) и Центра мозга, разума и машин (CBMM).
Новая модель утверждает, что, когда мозг получает визуальную информацию, он быстро выполняет серию вычислений, которые обратны шагам, которые программа компьютерной графики использовала бы для создания двухмерного представления лица или другого объекта. Этот тип модели, известный как эффективная инверсная графика (ЭИГ), также хорошо коррелирует с электрическими записями из избирательных по лицу областей мозга нечеловеческих приматов, предполагая, что зрительная система приматов может быть организована во многом так же, как компьютерная модель. , говорят исследователи.
, говорят исследователи.
Илькер Йилдирим, бывший постдоктор Массачусетского технологического института, ныне доцент кафедры психологии Йельского университета, является ведущим автором статьи, опубликованной сегодня в журнале Science Advances . Тененбаум и Винрих Фрайвальд, профессор неврологии и поведения в Университете Рокфеллера, являются старшими авторами исследования. Марио Белледонн, аспирант Йельского университета, также является автором.
Обратная графика
Десятилетия исследований зрительной системы мозга очень подробно изучили, как свет, поступающий на сетчатку, преобразуется в связные сцены.Это понимание помогло исследователям искусственного интеллекта разработать компьютерные модели, которые могут воспроизводить аспекты этой системы, такие как распознавание лиц или других объектов.
«Зрение — это функциональный аспект мозга, который мы понимаем лучше всего у людей и других животных», — говорит Тененбаум. «И компьютерное зрение — одна из самых успешных областей ИИ на данный момент. Мы считаем само собой разумеющимся, что машины теперь могут смотреть на изображения и очень хорошо распознавать лица, а также обнаруживать другие виды объектов.»
«И компьютерное зрение — одна из самых успешных областей ИИ на данный момент. Мы считаем само собой разумеющимся, что машины теперь могут смотреть на изображения и очень хорошо распознавать лица, а также обнаруживать другие виды объектов.»
Однако даже эти сложные системы искусственного интеллекта не могут сравниться с тем, что может сделать человеческая зрительная система, говорит Йилдирим.
«Наш мозг не просто обнаруживает, что там есть объект, или распознает и навешивает на что-то ярлык, — говорит он. «Мы видим все формы, геометрию, поверхности, текстуры. Мы видим очень богатый мир».
Более века назад врач, физик и философ Герман фон Гельмгольц предположил, что мозг создает эти богатые образы, обращая процесс формирования образов.Он предположил, что зрительная система включает в себя генератор изображений, который можно использовать, например, для воспроизведения лиц, которые мы видим во сне. Исследователи говорят, что запуск этого генератора в обратном направлении позволит мозгу работать в обратном направлении от изображения и сделать вывод, какое лицо или другой объект будет создавать это изображение.
Однако оставался вопрос: как мозг мог так быстро выполнять этот процесс, известный как инверсная графика? Ученые-компьютерщики пытались создать алгоритмы, которые могли бы выполнить этот подвиг, но лучшие предыдущие системы требуют многих циклов итеративной обработки, что занимает гораздо больше времени, чем 100–200 миллисекунд, которые требуются мозгу для создания подробного визуального представления того, что вы видите.Нейробиологи считают, что восприятие в мозгу может происходить так быстро, потому что оно реализуется в основном в виде прямого прохождения через несколько иерархически организованных слоев нейронной обработки.
Команда под руководством Массачусетского технологического института приступила к созданию особого типа модели глубокой нейронной сети, чтобы показать, как нейронная иерархия может быстро вывести основные черты сцены — в данном случае, конкретное лицо. В отличие от стандартных глубоких нейронных сетей, используемых в компьютерном зрении, которые обучаются на размеченных данных, указывающих класс объекта на изображении, сеть исследователей обучается на модели, отражающей внутренние представления мозга о том, какие сцены с лицами могут выглядит как.
Таким образом, их модель учится обращать шаги, выполняемые программой компьютерной графики для создания лиц. Эти графические программы начинают с трехмерного представления отдельного лица, а затем преобразуют его в двухмерное изображение, как оно видно с определенной точки зрения. Эти изображения могут быть размещены на произвольном фоновом изображении. Исследователи предполагают, что зрительная система мозга может делать что-то подобное, когда вы мечтаете или вызываете в воображении образ чьего-то лица.
Исследователи обучили свою глубокую нейронную сеть выполнять эти шаги в обратном порядке, то есть она начинала с двухмерного изображения, а затем добавляла такие функции, как текстура, кривизна и освещение, чтобы создать то, что исследователи называют «2,5D». представление. Эти 2,5D-изображения определяют форму и цвет лица с определенной точки зрения. Затем они преобразуются в трехмерные представления, которые не зависят от точки обзора.
«Модель дает системный учет обработки лиц в мозгу, позволяя ему видеть изображение и, в конечном итоге, получать трехмерный объект, который включает в себя представления формы и текстуры, через этот важный промежуточный этап 2. 5D-изображение», — говорит Йилдирим.
5D-изображение», — говорит Йилдирим.
Исполнение модели
Исследователи обнаружили, что их модель согласуется с данными, полученными при изучении определенных областей мозга макак. В исследовании, опубликованном в 2010 году, Фрейвальд и Дорис Цао из Калифорнийского технологического института зафиксировали активность нейронов в этих областях и проанализировали, как они реагировали на 25 разных лиц, увиденных с семи разных точек зрения. Это исследование выявило три этапа высокоуровневой обработки лиц, которые, как теперь предполагает команда Массачусетского технологического института, соответствуют трем этапам их инверсной графической модели: грубо говоря, 2.этап, зависящий от точки зрения 5D; этап, соединяющий 2,5-мерное пространство с 3-мерным; и трехмерный, инвариантный к точке обзора этап представления лица.
«Мы показываем, что как количественные, так и качественные характеристики реакции этих трех уровней мозга, по-видимому, удивительно хорошо согласуются с тремя верхними уровнями сети, которую мы построили», — говорит Тененбаум.
Исследователи также сравнили производительность модели с производительностью людей в задаче, которая включает в себя распознавание лиц с разных точек зрения.Эта задача усложняется, когда исследователи изменяют лица, удаляя текстуру лица, сохраняя его форму, или искажая форму, сохраняя относительную текстуру. Производительность новой модели была намного больше похожа на человеческую, чем компьютерные модели, используемые в современном программном обеспечении для распознавания лиц, что является дополнительным свидетельством того, что эта модель может быть ближе к имитации того, что происходит в зрительной системе человека.
Теперь исследователи планируют продолжить тестирование подхода к моделированию на дополнительных изображениях, в том числе на объектах, не являющихся лицами, чтобы выяснить, может ли инверсная графика объяснить, как мозг воспринимает другие виды сцен.Кроме того, они считают, что адаптация этого подхода к компьютерному зрению может привести к повышению производительности систем ИИ.
«Если мы сможем показать доказательства того, что эти модели могут соответствовать тому, как работает мозг, эта работа может побудить исследователей компьютерного зрения более серьезно отнестись и вложить больше инженерных ресурсов в этот инверсионно-графический подход к восприятию», — говорит Тененбаум. «Мозг по-прежнему является золотым стандартом для любой машины, которая видит мир насыщенно и быстро».
Преодоление разрыва между человеческим и машинным зрением
Дополнительная информация: «Эффективная инверсная графика в биологической обработке лиц» Science Advances (2020).advances.sciencemag.org/content/6/10/eaax5979 Предоставлено Массачусетский Институт Технологий
Цитата :
Компьютерная модель обработки лица может показать, как мозг так быстро создает детализированные визуальные представления (5 марта 2020 г.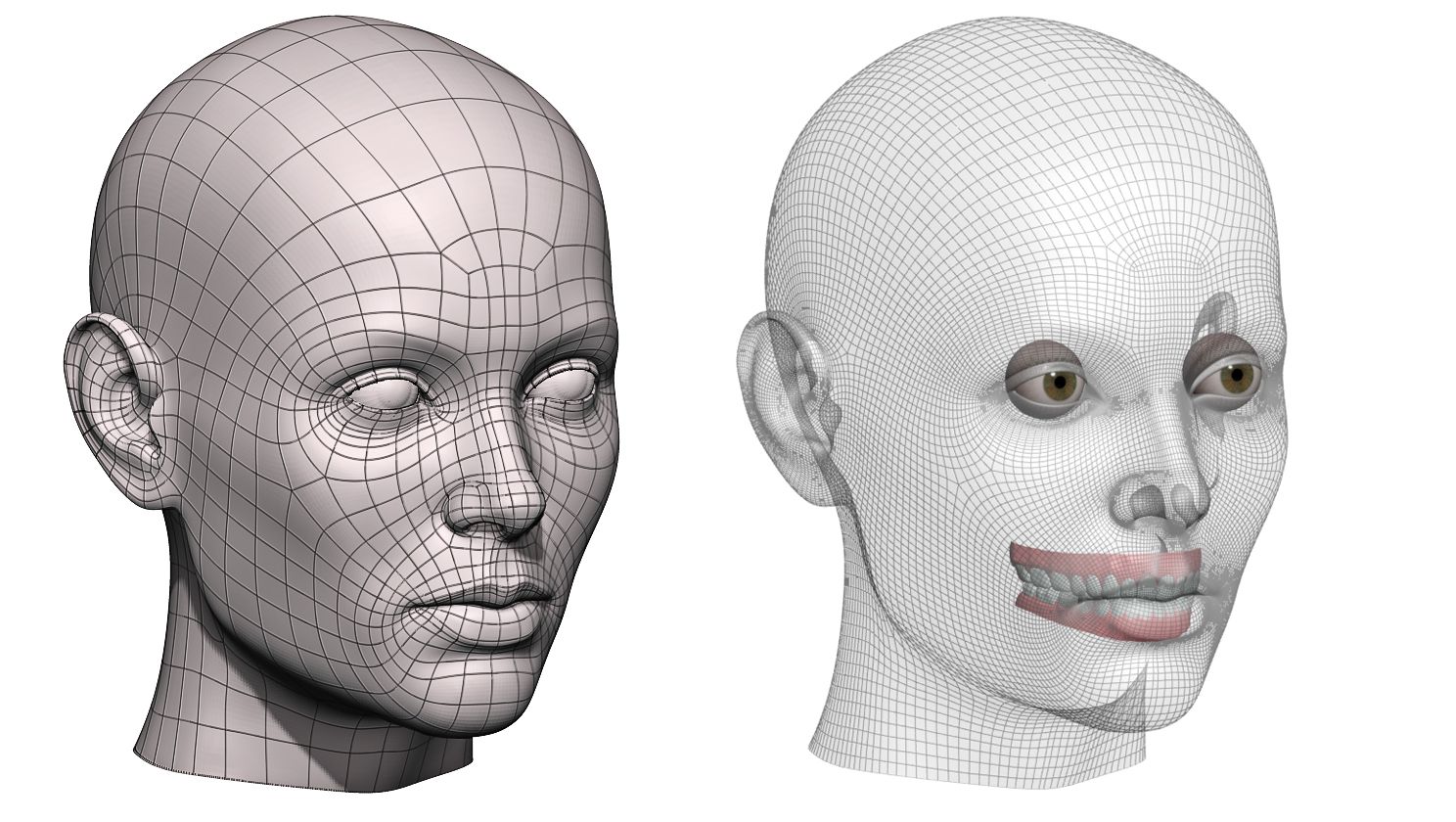 )
получено 26 января 2022 г.
с https://techxplore.com.com/news/2020-03-reveal-brain-richly-visual-representations.html
)
получено 26 января 2022 г.
с https://techxplore.com.com/news/2020-03-reveal-brain-richly-visual-representations.html
Этот документ защищен авторским правом. Помимо любой добросовестной сделки с целью частного изучения или исследования, никакие часть может быть воспроизведена без письменного разрешения. Контент предоставляется только в ознакомительных целях.
Практический подход к художественному 3D-моделированию лица с воплощением идентичности
В этом документе описывается практический метод художественного 3D-моделирования лица.
где человеческая личность может быть вставлена в трехмерное художественное лицо. Этот подход может автоматически извлекать человеческую личность из
3D-модель человеческого лица, а затем перенести ее в 3D-художественное лицо
модель контролируемым образом. Его основная идея состоит в том, чтобы построить лицо
пространство геометрии и пространство текстуры лица на основе предварительно собранного
3D набор данных лица. Затем эти пространства используются для извлечения и смешивания
модели лица вместе на основе их лица и стилей.
Этот подход может позволить начинающему пользователю интерактивно генерировать
различные художественные лица быстро с помощью ползунка.Кроме того, он может запускаться в
в режиме реального времени на стандартном компьютере без GPU-ускорения.
Этот подход может быть широко использован в различных 3D художественных лицах.
приложения для моделирования, такие как быстрое создание мультяшной толпы
с разными героями мультфильмов.
Этот подход может автоматически извлекать человеческую личность из
3D-модель человеческого лица, а затем перенести ее в 3D-художественное лицо
модель контролируемым образом. Его основная идея состоит в том, чтобы построить лицо
пространство геометрии и пространство текстуры лица на основе предварительно собранного
3D набор данных лица. Затем эти пространства используются для извлечения и смешивания
модели лица вместе на основе их лица и стилей.
Этот подход может позволить начинающему пользователю интерактивно генерировать
различные художественные лица быстро с помощью ползунка.Кроме того, он может запускаться в
в режиме реального времени на стандартном компьютере без GPU-ускорения.
Этот подход может быть широко использован в различных 3D художественных лицах.
приложения для моделирования, такие как быстрое создание мультяшной толпы
с разными героями мультфильмов.
1. Введение
Моделирование трехмерного художественного лица с определенной характеристикой — нетривиальная задача даже для опытных художников. Существующие методы создания лица, которые часто манипулируют, деформируют или преувеличивают исходную модель лица, потенциально могут быть использованы для этой цели.Однако эти методы обычно требуют от пользователей настройки внутренних параметров 3D-лица или изучения статистических моделей из набора нарисованных художником примеров. Помимо кропотливых проб и ошибок, требуемых этими методами, для пользователей очень сложно, если не невозможно, легко контролировать уровень идентичности лица во время процесса скульптуры.
Существующие методы создания лица, которые часто манипулируют, деформируют или преувеличивают исходную модель лица, потенциально могут быть использованы для этой цели.Однако эти методы обычно требуют от пользователей настройки внутренних параметров 3D-лица или изучения статистических моделей из набора нарисованных художником примеров. Помимо кропотливых проб и ошибок, требуемых этими методами, для пользователей очень сложно, если не невозможно, легко контролировать уровень идентичности лица во время процесса скульптуры.
Коммерческие приложения предоставляют инструменты для трехмерного моделирования аватара лица в других направлениях, например, просят пользователей вручную составить лицевые компоненты из списка готовых шаблонов (например,g., Second Life) или для линейного преобразования человеческого лица в лицо монстра (например, http://www.evolver.com/). Тем не менее, насколько нам известно, все эти подходы не предоставляют пользователям простого контроля для настройки уровня человеческой идентичности при попытке автоматически сохранить исходный художественный стиль.
В этой статье мы представляем практический подход к трехмерному художественному моделированию лица с воплощением идентичности с помощью алгоритмов автоматического смешивания идентичности человека. В этой работе человеческая идентичность относится к коэффициентам PCA из проекции модели человеческого лица в подпространстве PCA (которое построено из набора человеческих лиц).Мультяшный стиль относится к коэффициентам PCA из проекции мультяшной модели лица плюс остатки за пределами подпространства PCA (где остатки = мультяшная модель лица — реконструированная проекция PCA). Остатки добавляются к мультяшному стилю, потому что, как правило, мультяшное лицо содержит много важных черт лица (стилей), выпадающих из диапазона подпространства PCA человека.
Как показано на рис. 2, эта автоматическая система (показана на рис. 1) состоит из следующих трех основных этапов.(i) Учитывая входное трехмерное человеческое лицо (называемое человеческим лицом лицом или далее сокращенно HI-face в этом документе) и входное трехмерное художественное лицо (называемое художественным стилем лица или далее сокращенно как AS-face ), как HI-face, так и AS-face проецируются на уменьшенные подпространства PCA. (ii) Пользователи могут в интерактивном режиме настраивать ползунок для управления воплощенными уровнями HI-лица на AS-лице с помощью нашего представленного алгоритма разработки идентичности (IE).(iii) Результирующая 3D-художественная модель лица автоматически строится с помощью наших алгоритмов синтеза 3D-поверхности и текстуры. В ходе нашего эксперимента мы обнаружили, что наш подход может синтезировать различные желаемые персонажи, воплощенные в индивидуальности, сохраняя при этом художественные стили.
(ii) Пользователи могут в интерактивном режиме настраивать ползунок для управления воплощенными уровнями HI-лица на AS-лице с помощью нашего представленного алгоритма разработки идентичности (IE).(iii) Результирующая 3D-художественная модель лица автоматически строится с помощью наших алгоритмов синтеза 3D-поверхности и текстуры. В ходе нашего эксперимента мы обнаружили, что наш подход может синтезировать различные желаемые персонажи, воплощенные в индивидуальности, сохраняя при этом художественные стили.
Оставшаяся часть этого документа организована следующим образом. Раздел 2 содержит краткий обзор недавних усилий, наиболее связанных с этой работой. Раздел 3 описывает этап автономной обработки данных в нашем подходе. Раздел 4 описывает основные алгоритмы, используемые в этой работе.В разделе 5 подробно описаны процессы геометрической деформации и синтеза текстуры. Экспериментальные результаты нашего подхода представлены в Разделе 6. Наконец, ограничения, будущие направления и заключительные замечания представлены в Разделе 7. этой бумаги. Заинтересованные читатели могут обратиться к недавнему обзору [1]. В этом разделе мы кратко рассмотрим основные усилия в двух соответствующих областях исследований: мультипликационное/карикатурное моделирование и трехмерное моделирование/деформация лица.
этой бумаги. Заинтересованные читатели могут обратиться к недавнему обзору [1]. В этом разделе мы кратко рассмотрим основные усилия в двух соответствующих областях исследований: мультипликационное/карикатурное моделирование и трехмерное моделирование/деформация лица.
2.1. Мультяшное/карикатурное моделирование
Наша работа направлена на моделирование мультяшного лица. Однако у него есть несколько общих черт с карикатурным моделированием, поскольку оба они создают лицо, отражающее человеческую идентичность. В то время как карикатурное моделирование пытается преувеличить идентичность человеческого лица для лучшего общения [2], моделирование мультяшного лица пытается сохранить художественный стиль, чтобы подчеркнуть свой мультяшный характер.
В качестве самой ранней задокументированной попытки создать компьютерную карикатуру Бреннан [3] создает двухмерный карикатурный эскиз, преувеличивая (масштабируя) рисунок всего лица по отношению к среднему человеческому лицу. Позже Косимидзу и соавт. [4] представляют аналогичную систему PICASSO для создания карикатуры на основе 2D-изображения. Хсу и Джайн [5] используют интерактивный алгоритм змей для обнаружения компонентов лица, а затем создают двухмерный карикатурный эскиз, масштабируя его отличие от среднего лица. Мо и др. [6] создают 2D-карикатурный эскиз, преувеличивая каждую часть лица на основе ее стандартного отклонения. В последние годы были предложены методы создания карикатур на основе примеров для изучения стиля рисования художников с использованием различных статистических данных и алгоритмов машинного обучения, например, частичное обучение на основе наименьших квадратов [7], отображение собственного пространства [8], координаты среднего значения [9] и расстояние золотого сечения [10].Кроме того, Аклеман и Райш [11] предлагают общую пятиэтапную процедуру для создания стильной трехмерной карикатуры вручную. Из предварительно собранных примеров портретов произведений искусства многие подходы, основанные на данных [12–16], создают портрет произведения искусства исключительно из новой фотографии.
Позже Косимидзу и соавт. [4] представляют аналогичную систему PICASSO для создания карикатуры на основе 2D-изображения. Хсу и Джайн [5] используют интерактивный алгоритм змей для обнаружения компонентов лица, а затем создают двухмерный карикатурный эскиз, масштабируя его отличие от среднего лица. Мо и др. [6] создают 2D-карикатурный эскиз, преувеличивая каждую часть лица на основе ее стандартного отклонения. В последние годы были предложены методы создания карикатур на основе примеров для изучения стиля рисования художников с использованием различных статистических данных и алгоритмов машинного обучения, например, частичное обучение на основе наименьших квадратов [7], отображение собственного пространства [8], координаты среднего значения [9] и расстояние золотого сечения [10].Кроме того, Аклеман и Райш [11] предлагают общую пятиэтапную процедуру для создания стильной трехмерной карикатуры вручную. Из предварительно собранных примеров портретов произведений искусства многие подходы, основанные на данных [12–16], создают портрет произведения искусства исключительно из новой фотографии. Эти работы в основном отражают связь художественного стиля произведения искусства и его фотографии из многих примеров, чтобы воссоздать новое произведение искусства. Недавно Бергер и соавт. [16] синтезируют различные художественные стили, а также уровни абстракции портретных зарисовок, используя коллекцию произведений художника.Однако ни один из этих подходов не предлагает инструмента для изменения идентичности художественного лица, сохраняя при этом художественный стиль как можно более нетронутым. Кроме того, пользователи также могут вводить в нашу систему любые новые художественные образы, не ограничиваясь предопределенными стилями, как в других подходах.
Эти работы в основном отражают связь художественного стиля произведения искусства и его фотографии из многих примеров, чтобы воссоздать новое произведение искусства. Недавно Бергер и соавт. [16] синтезируют различные художественные стили, а также уровни абстракции портретных зарисовок, используя коллекцию произведений художника.Однако ни один из этих подходов не предлагает инструмента для изменения идентичности художественного лица, сохраняя при этом художественный стиль как можно более нетронутым. Кроме того, пользователи также могут вводить в нашу систему любые новые художественные образы, не ограничиваясь предопределенными стилями, как в других подходах.
2.2. Трехмерное моделирование/деформация лица
Ранние попытки трехмерного моделирования лица обычно основывались на нескольких изображениях [17]. За счет сбора непрерывных деталей деформации поверхности последние достижения в области захвата производительности могут создавать высокоточные последовательности 3D-сеток лица на основе действий человека, включая захват с несколькими разрешениями [18], захват на основе стереокамер [19, 20] и структурированный свет. захват [21].Исследователи также разработали множество алгоритмов, интерфейсов и инструментов, позволяющих пользователям напрямую манипулировать 3D-моделями лицевой сетки [22, 23]. Недавние алгоритмы редактирования и деформации лиц на основе данных используют статистические корреляции в предварительно собранных наборах лицевых данных [24–28]. Примечательно, что Бланц и Веттер [29] построили 3D-морфируемую модель лица, создав пространства анализа основных компонентов (PCA) из 3D-геометрии и текстуры отсканированного набора данных 3D-лица и продемонстрировав, что построенные пространства PCA лица можно использовать для различных синтезов лица. и редактирования приложений.Кроме того, были разработаны кукольные методы прямого управления позами лица на основе живого выступления актера/актрисы [30–34]. Однако все эти методы ориентированы на моделирование реалистичных 3D-моделей обычных человеческих лиц, и ни один из них не может автоматически переносить или встраивать идентичность человеческого лица в 3D-художественное лицо.
захват [21].Исследователи также разработали множество алгоритмов, интерфейсов и инструментов, позволяющих пользователям напрямую манипулировать 3D-моделями лицевой сетки [22, 23]. Недавние алгоритмы редактирования и деформации лиц на основе данных используют статистические корреляции в предварительно собранных наборах лицевых данных [24–28]. Примечательно, что Бланц и Веттер [29] построили 3D-морфируемую модель лица, создав пространства анализа основных компонентов (PCA) из 3D-геометрии и текстуры отсканированного набора данных 3D-лица и продемонстрировав, что построенные пространства PCA лица можно использовать для различных синтезов лица. и редактирования приложений.Кроме того, были разработаны кукольные методы прямого управления позами лица на основе живого выступления актера/актрисы [30–34]. Однако все эти методы ориентированы на моделирование реалистичных 3D-моделей обычных человеческих лиц, и ни один из них не может автоматически переносить или встраивать идентичность человеческого лица в 3D-художественное лицо. Недавно Sucontphunt и Neumann [35] синтезировали трехмерное художественное лицо, комбинируя черты лица из эскизного портрета с поверхностью и текстурой художественного примера лица.Однако эта работа просто искажает художественный пример лица, чтобы он соответствовал чертам лица. Поверхность результирующего трехмерного художественного лица представляет собой случайную смесь ограничений характерных точек и примера художественного лица. Напротив, наша работа интерпретирует идентичность человеческого лица, а также стиль художественного лица и предоставляет контроллер для их систематического смешивания.
Недавно Sucontphunt и Neumann [35] синтезировали трехмерное художественное лицо, комбинируя черты лица из эскизного портрета с поверхностью и текстурой художественного примера лица.Однако эта работа просто искажает художественный пример лица, чтобы он соответствовал чертам лица. Поверхность результирующего трехмерного художественного лица представляет собой случайную смесь ограничений характерных точек и примера художественного лица. Напротив, наша работа интерпретирует идентичность человеческого лица, а также стиль художественного лица и предоставляет контроллер для их систематического смешивания.
2.3. Интерполяция формы
Методы интерполяции формы направлены на семантическое преобразование промежуточной формы путем смешивания примеров форм вместе.Линейная интерполяция по позициям вершин проста и быстра, но страдает нелинейным характером частей с большим вращением между фигурами-примерами. Самнер и др. [36] интерполируют 3D-формы из примера 3D-форм, используя инвариантное к вращению пространство формы, проецируя формы в пространство формы с линейным масштабированием и сдвигом и пространство формы с линейно-логарифмическим вращением с градиентом деформации [24]. Винклер и др. [37] интерполируют трехмерные формы, перемещая иерархию форм от глобального к локальному масштабу, фокусируясь на длинах ее ребер и двугранных углах [38], чтобы сформировать инвариантные к перемещению и вращению пространства форм.Маррас и др. [39] разделяют 3D-форму на линейные и нелинейные интерполируемые сегменты, чтобы правильно их интерполировать и сэкономить время вычислений. Эти методы создают впечатляющие правдоподобные 3D-формы в диапазоне заданных 3D-образцов. Однако ни один из этих методов не фокусируется на сохранении уникальных особенностей (3D-идентификация лица и 3D-художественный стиль в нашем случае) промежуточной 3D-формы в процессе интерполяции.
Винклер и др. [37] интерполируют трехмерные формы, перемещая иерархию форм от глобального к локальному масштабу, фокусируясь на длинах ее ребер и двугранных углах [38], чтобы сформировать инвариантные к перемещению и вращению пространства форм.Маррас и др. [39] разделяют 3D-форму на линейные и нелинейные интерполируемые сегменты, чтобы правильно их интерполировать и сэкономить время вычислений. Эти методы создают впечатляющие правдоподобные 3D-формы в диапазоне заданных 3D-образцов. Однако ни один из этих методов не фокусируется на сохранении уникальных особенностей (3D-идентификация лица и 3D-художественный стиль в нашем случае) промежуточной 3D-формы в процессе интерполяции.
3. Автономная обработка данных
В нашем подходе используется предварительно собранный трехмерный набор данных о человеческом лице [40], состоящий из 100 человек (56 женщин и 44 мужчин) в возрасте от 18 до 70 лет, принадлежащих к разным этническим группам.Каждая запись в наборе данных состоит из трехмерной сетки лица и соответствующей текстуры. Мы обрабатываем набор данных лиц в автономном режиме следующим образом. Во-первых, чтобы построить соответствие для всех 3D-моделей лица в наборе данных, мы выбираем модель лица вне набора данных как эталонное лицо . Затем мы совмещаем все грани с эталонной гранью, используя алгоритм переноса деформации, предложенный Самнером и Поповичем [24]. В итоге все зарегистрированные лица имеют ту же топологию, что и эталонное лицо.Чтобы статистически представить человеческую идентичность, мы строим два сокращенных подпространства PCA из набора данных следующим образом.
Мы обрабатываем набор данных лиц в автономном режиме следующим образом. Во-первых, чтобы построить соответствие для всех 3D-моделей лица в наборе данных, мы выбираем модель лица вне набора данных как эталонное лицо . Затем мы совмещаем все грани с эталонной гранью, используя алгоритм переноса деформации, предложенный Самнером и Поповичем [24]. В итоге все зарегистрированные лица имеют ту же топологию, что и эталонное лицо.Чтобы статистически представить человеческую идентичность, мы строим два сокращенных подпространства PCA из набора данных следующим образом.
3.1. Face Geometry Subspace
Геометрическая идентичность каждого трехмерного лица кодируется как трехмерное аффинное преобразование между лицом и средним человеческим лицом. Мы кодируем деформацию лица (т. е. отличие от среднего человеческого лица) как аффинные преобразования, а не наивные смещения вершин, потому что первые создают более гладкие поверхности в процессе смешивания.На рис. 3 показаны примеры результатов различных представлений поверхностей при смешивании поверхностей со случайными коэффициентами масштабирования. Для расчета аффинных преобразований для каждой сетки лица мы используем алгоритм градиента деформации [24], поскольку трехмерное лицо не содержит большого смещения, и этот алгоритм работает за линейное время. Затем пространства PCA строятся из полученных данных аффинного преобразования всех граней.
Для расчета аффинных преобразований для каждой сетки лица мы используем алгоритм градиента деформации [24], поскольку трехмерное лицо не содержит большого смещения, и этот алгоритм работает за линейное время. Затем пространства PCA строятся из полученных данных аффинного преобразования всех граней.
Одна из важных проблем при использовании матриц аффинного преобразования заключается в том, что они не могут быть линейно интерполированы, в то время как точки данных в пространстве PCA должны быть интерполированы линейно.В этой работе мы разлагаем матрицу аффинного преобразования на компонент вращения , и компонент масштабирования , используя полярное разложение. Затем мы также используем экспоненциальную карту для преобразования в ее логарифмическое пространство, чтобы обеспечить его свойство линейной интерполяции, как в структуре MeshIK [36]. Для каждой сетки лица мы объединяем и всех вершин, чтобы сформировать два вектора соответственно. В завершение по всем полученным векторам построим два усеченных подпространства PCA, а именно, и . В этой работе мы сохраняем 99 наиболее значимых собственных векторов для построения каждого усеченного подпространства PCA.
В этой работе мы сохраняем 99 наиболее значимых собственных векторов для построения каждого усеченного подпространства PCA.
3.2. Подпространство текстуры лица
Аналогичным образом мы также строим подпространство PCA текстуры лица на основе текстур всех лиц в наборе данных. В этом процессе используется только информация о тоне, представленная компонентами цветового пространства HSV текстур лица, чтобы избежать цветовых артефактов. Цветовые артефакты в основном являются результатом смешивания нечеловеческого цвета лица AS с человеческой текстурой лица HI в цветовом пространстве RGB (более подробно это будет обсуждаться в разделе 5).Кроме того, чтобы предотвратить очевидные цветовые артефакты из процесса смешивания, аналогичного геометрической части, текстура представлена градиентом изображения среднего человеческого лица, а не прямыми значениями пикселей.
4. Алгоритм разработки идентичности
Поскольку подпространство PCA является линейным, мы называем спроецированные коэффициенты PCA лица его вектором признаков. В этом подпространстве мы можем интерполировать два вектора признаков, чтобы объединить два лица вместе. Однако просто объединенная/интерполированная грань может легко потерять основные характеристики обеих граней, как показано на рисунке 4.Кроме того, если мы перенесем HI-грань на AS-грань, используя технику передачи формы, такую как перенос деформации [24], результирующая грань будет неуправляемо смешана между AS-гранью и HI-гранью, как показано на рисунке. 4 (только геометрические) и рис. 12 (с текстурой).
В этом подпространстве мы можем интерполировать два вектора признаков, чтобы объединить два лица вместе. Однако просто объединенная/интерполированная грань может легко потерять основные характеристики обеих граней, как показано на рисунке 4.Кроме того, если мы перенесем HI-грань на AS-грань, используя технику передачи формы, такую как перенос деформации [24], результирующая грань будет неуправляемо смешана между AS-гранью и HI-гранью, как показано на рисунке. 4 (только геометрические) и рис. 12 (с текстурой).
По указанной выше причине мы вводим алгоритм разработки идентичности (IE), который фиксирует уникальность HI-лица и автоматически передает его на AS-лицо. Эта методика включает в себя возможность управления уровнем уникальности HI-лица.Алгоритм IE состоит из подготовки данных, выбора идентичности и этапов передачи идентичности.
На этапе подготовки данных мы сначала регистрируем как входную HI-грань, так и AS-грань с эталонной моделью грани посредством переноса деформации [24], как и на этапе автономной обработки данных (раздел 3). Затем извлекаются аффинные преобразования всех треугольников зарегистрированных HI-граней и AS-граней. Наконец, компоненты двух граней преобразуются в два вектора признаков PCA путем проецирования их на предварительно сконструированное подпространство PCA, .Аналогичные преобразования PCA применяются к компоненту S и компоненту текстуры (). Поскольку алгоритм IE необходимо применять к компонентам , и по отдельности; для удобства мы используем (или ) для обозначения полученного вектора признаков PCA HI-грани (или AS-грани).
Затем извлекаются аффинные преобразования всех треугольников зарегистрированных HI-граней и AS-граней. Наконец, компоненты двух граней преобразуются в два вектора признаков PCA путем проецирования их на предварительно сконструированное подпространство PCA, .Аналогичные преобразования PCA применяются к компоненту S и компоненту текстуры (). Поскольку алгоритм IE необходимо применять к компонентам , и по отдельности; для удобства мы используем (или ) для обозначения полученного вектора признаков PCA HI-грани (или AS-грани).
На шаге выбора идентификатора для определения уникальности лица вероятность человека в его пространстве PCA вычисляется по (1) [41]. Учитывать где — количество собственных векторов, — собственное значение, а — коэффициент вектора признаков.есть вероятность , которая определяет сходство между лицом и средним человеческим лицом. Низкий (т. е. высокий) означает, что лицо очень уникально (некоторые черты лица отличают его от обычного лица). Таким образом, показатель уникальности th-го коэффициента можно просто вычислить по (2). Эти баллы уникальности являются основными критериями для выбора коэффициентов, которые следует перенести в . Чтобы сделать оценки сопоставимыми, оценки нормализуются к диапазону и объединяются в один вектор.Мы называем этот конкатенированный вектор вектором оценки :
Эти баллы уникальности являются основными критериями для выбора коэффициентов, которые следует перенести в . Чтобы сделать оценки сопоставимыми, оценки нормализуются к диапазону и объединяются в один вектор.Мы называем этот конкатенированный вектор вектором оценки :
На этапе передачи идентичности , если какое-либо значение в векторе оценки (т. е. оценка уникальности th-го коэффициента) больше заданного пользователем порога (с помощью ползунка), то соответствующие коэффициенты будут быть переданы для создания результирующего вектора, как описано в Алгоритме 1. Поэтому, когда пользователи перемещают ползунок справа налево, результирующее лицо будет постепенно раскрывать больше идентичности HI-лица.На рис. 5 показаны различные результирующие грани при изменении значения ползунка. На рис. 6 показаны трехмерные геометрические виды двух результирующих художественных лиц (значение ползунка установлено на 0,5). Наконец, мы возвращаемся к их матрице аффинного преобразования и текстурным пространствам, которые используются в последующих разделах для восстановления результирующего трехмерного лица и его текстуры.
| |||||||||||||||||||||
 Эта оптимизация разреженной матрицы может быть решена с помощью алгоритма факторизации Холецкого [24] для ускорения процесса.
Эта оптимизация разреженной матрицы может быть решена с помощью алгоритма факторизации Холецкого [24] для ускорения процесса. Это создаст текстуру лица, которая содержит внешний вид AS-лица с тоном HI-лица. Однако, если необходимо также сохранить человеческий базовый цвет, мы можем интерполировать значение оттенка, которое предпочитает оттенок художника человеческому оттенку, например, используя квадратичную интерполяцию.На рис. 7 сравнивается процесс синтеза художественной текстуры лица при использовании цветового пространства RGB или HSV. Таким образом, алгоритм IE выполняется только для каналов и каналов, закодированных в .
Это создаст текстуру лица, которая содержит внешний вид AS-лица с тоном HI-лица. Однако, если необходимо также сохранить человеческий базовый цвет, мы можем интерполировать значение оттенка, которое предпочитает оттенок художника человеческому оттенку, например, используя квадратичную интерполяцию.На рис. 7 сравнивается процесс синтеза художественной текстуры лица при использовании цветового пространства RGB или HSV. Таким образом, алгоритм IE выполняется только для каналов и каналов, закодированных в . Таким образом, целью нашей оценки является проверка вариативности синтезированных художественных лиц. Художественные лица, синтезированные из одного и того же AS-лица с определенным HI-лицом, должны напоминать это конкретное HI-лицо, а не другие HI-лица.
Таким образом, целью нашей оценки является проверка вариативности синтезированных художественных лиц. Художественные лица, синтезированные из одного и того же AS-лица с определенным HI-лицом, должны напоминать это конкретное HI-лицо, а не другие HI-лица. В этом исследовании приняли участие семнадцать студентов-добровольцев, изучающих информатику. Он состоял из 11 анкет, в каждой из которых участников просили выбрать художественное лицо, которое больше всего напоминает введенное человеческое лицо, из 3 других кандидатов в том же художественном стиле (остальные 2 кандидата выбираются случайным образом из результатов), как показано на рисунке. 11. Эксперименты проводятся для нашей методики и для методики линейной интерполяции отдельно.
В этом исследовании приняли участие семнадцать студентов-добровольцев, изучающих информатику. Он состоял из 11 анкет, в каждой из которых участников просили выбрать художественное лицо, которое больше всего напоминает введенное человеческое лицо, из 3 других кандидатов в том же художественном стиле (остальные 2 кандидата выбираются случайным образом из результатов), как показано на рисунке. 11. Эксперименты проводятся для нашей методики и для методики линейной интерполяции отдельно. Для метода линейной интерполяции средняя скорость распознавания составляет 62,1%, а стандартное отклонение — 27.3. Для мажоритарной схемы правильно ответили 7 из 11. Примеры результатов линейной интерполяции показаны на рисунке 12.
Для метода линейной интерполяции средняя скорость распознавания составляет 62,1%, а стандартное отклонение — 27.3. Для мажоритарной схемы правильно ответили 7 из 11. Примеры результатов линейной интерполяции показаны на рисунке 12.
 Эта проблема ограничивает возможности захвата личности с помощью нашего подхода. Во-вторых, наш нынешний подход не может справиться с созданием различных выражений лица и анимаций на результирующих художественных лицах, хотя анимация не находится в центре внимания текущей работы.Расширяя существующие методы перенацеливания выражения лица и анимации, мы ожидаем, что реалистичные выражения лица и анимация могут быть хорошо воспроизведены на результирующих художественных моделях лица.
Эта проблема ограничивает возможности захвата личности с помощью нашего подхода. Во-вторых, наш нынешний подход не может справиться с созданием различных выражений лица и анимаций на результирующих художественных лицах, хотя анимация не находится в центре внимания текущей работы.Расширяя существующие методы перенацеливания выражения лица и анимации, мы ожидаем, что реалистичные выражения лица и анимация могут быть хорошо воспроизведены на результирующих художественных моделях лица.
 querySelector(«.цена-варианта-покупки»)
подписка.classList.remove(«расширенный»)
var form = подписка.querySelector(«.форма-варианта-покупки»)
var priceInfo = подписка.селектор запросов(«.Информация о цене»)
var PurchaseOption = toggle.parentElement если (переключить && форма && priceInfo) {
toggle.setAttribute(«роль», «кнопка»)
toggle.setAttribute(«tabindex», «0») toggle.addEventListener («щелчок», функция (событие) {
var expand = toggle.getAttribute(«aria-expanded») === «true» || ложный
переключать.setAttribute(«расширенная ария», !расширенная)
form.hidden = расширенный
если (! расширено) {
покупкаOption.classList.add(«расширенный»)
} еще {
покупкаOption.
querySelector(«.цена-варианта-покупки»)
подписка.classList.remove(«расширенный»)
var form = подписка.querySelector(«.форма-варианта-покупки»)
var priceInfo = подписка.селектор запросов(«.Информация о цене»)
var PurchaseOption = toggle.parentElement если (переключить && форма && priceInfo) {
toggle.setAttribute(«роль», «кнопка»)
toggle.setAttribute(«tabindex», «0») toggle.addEventListener («щелчок», функция (событие) {
var expand = toggle.getAttribute(«aria-expanded») === «true» || ложный
переключать.setAttribute(«расширенная ария», !расширенная)
form.hidden = расширенный
если (! расширено) {
покупкаOption.classList.add(«расширенный»)
} еще {
покупкаOption. classList.remove(«расширенный»)
}
priceInfo.hidden = расширенный
}, ложный)
}
} функция initKeyControls() {
документ.addEventListener(«keydown», функция (событие) {
if (document.activeElement.classList.contains(«цена-варианта-покупки») && (event.code === «Пробел» || event.code === «Enter»)) {
если (document.activeElement) {
событие.preventDefault()
документ.activeElement.click()
}
}
}, ложный)
} функция InitialStateOpen() {
var buyboxWidth = buybox.смещениеШирина
;[].slice.call(buybox.querySelectorAll(«.опция покупки»)).
classList.remove(«расширенный»)
}
priceInfo.hidden = расширенный
}, ложный)
}
} функция initKeyControls() {
документ.addEventListener(«keydown», функция (событие) {
if (document.activeElement.classList.contains(«цена-варианта-покупки») && (event.code === «Пробел» || event.code === «Enter»)) {
если (document.activeElement) {
событие.preventDefault()
документ.activeElement.click()
}
}
}, ложный)
} функция InitialStateOpen() {
var buyboxWidth = buybox.смещениеШирина
;[].slice.call(buybox.querySelectorAll(«.опция покупки»)). forEach(функция (опция, индекс) {
var toggle = option.querySelector(«.цена-варианта-покупки»)
var form = option.querySelector(«.форма-варианта-покупки»)
var priceInfo = option.querySelector(«.Информация о цене»)
если (buyboxWidth > 480) {
переключить.щелчок()
} еще {
если (индекс === 0) {
переключать.щелчок()
} еще {
toggle.setAttribute («ария-расширенная», «ложь»)
form.hidden = «скрытый»
priceInfo.hidden = «скрытый»
}
}
})
} начальное состояниеОткрыть() если (window.buyboxInitialized) вернуть
window.
forEach(функция (опция, индекс) {
var toggle = option.querySelector(«.цена-варианта-покупки»)
var form = option.querySelector(«.форма-варианта-покупки»)
var priceInfo = option.querySelector(«.Информация о цене»)
если (buyboxWidth > 480) {
переключить.щелчок()
} еще {
если (индекс === 0) {
переключать.щелчок()
} еще {
toggle.setAttribute («ария-расширенная», «ложь»)
form.hidden = «скрытый»
priceInfo.hidden = «скрытый»
}
}
})
} начальное состояниеОткрыть() если (window.buyboxInitialized) вернуть
window. buyboxInitialized = истина initKeyControls()
})()
buyboxInitialized = истина initKeyControls()
})() Ну, это довольно интуитивно просто распознавать лица, верно? Что ж, более формальное определение заключается в том, что обнаружение лиц — это технология, которая позволяет компьютерам идентифицировать человеческие лица на цифровых изображениях. Это тип обнаружения класса объектов, в котором задача состоит в том, чтобы найти расположение и размеры всех объектов на изображении, принадлежащих данному классу, в данном случае это лица.
Ну, это довольно интуитивно просто распознавать лица, верно? Что ж, более формальное определение заключается в том, что обнаружение лиц — это технология, которая позволяет компьютерам идентифицировать человеческие лица на цифровых изображениях. Это тип обнаружения класса объектов, в котором задача состоит в том, чтобы найти расположение и размеры всех объектов на изображении, принадлежащих данному классу, в данном случае это лица.
 Чтобы реализовать это, перейдите в Vision Store, нажмите «Распознавание лиц», убедитесь, что вы вошли в систему, в противном случае вы можете зарегистрироваться.
Чтобы реализовать это, перейдите в Vision Store, нажмите «Распознавание лиц», убедитесь, что вы вошли в систему, в противном случае вы можете зарегистрироваться. В первой части мы импортируем наши библиотеки, особенно библиотеки OpenCV и MediaPipe. Затем мы запускаем нашу веб-камеру или видео и устанавливаем порог достоверности обнаружения лиц, который регулирует чувствительность нашего детектора.
В первой части мы импортируем наши библиотеки, особенно библиотеки OpenCV и MediaPipe. Затем мы запускаем нашу веб-камеру или видео и устанавливаем порог достоверности обнаружения лиц, который регулирует чувствительность нашего детектора.
